(스터디) 실무로 통하는 인과추론 with 파이썬 - PART 1

[실무로 통하는 인과추론 with 파이썬]을 읽고 내용을 정리한다.
PART 1. 인과추론 기초
1장 인과추론 소개
연관관계(association)는 인과관계(causation)가 아니다. 하지만 연관관계는 때로 인과관계가 될 수도 있다.
- 연관관계: 두 개의 수치나 확률변수가 같이 움직이는 것
- 인과관계: 한 변수의 변화가 다른 변수의 변화를 일으키는 것
인과추론: 연관관계로부터 인과관계를 추론하고 언제, 그리고 왜 서로 다른지 이해하는 과학적 방법론
- 원인과 결과의 관계를 알아야만 원인에 개입하여 원하는 결과를 가져올 수 있다.

u: 모델 외부의 변수 (모델링하지 않을 변수)
T: 처치변수
←: 등호 대신 화살표를 사용하여 인과관계의 비가역성(nonreversibility)을 표시
Y ← f(T, u): 처치변수 T는 다른 외부 변수 u와 함께 함수 f를 통해 결과 Y를 유발한다.
do(.) 연산자
- 관측된 데이터에서 항상 얻을 수 없는 인과 추정량(causal quantity)을 정의하는데 사용
- T에 개입해서 어떤 일이 일어날지 추론하고 싶다: do(T=t0)

- do(.) 연산자를 사용하면 개별 실험 대상 i에 처치 T가 결과에 미치는 영향인 개별 처치효과(individual treatment effect, ITE)를 표현할 수 있다.
- 위의 식에 대입하면 Γ = Y|do(on sale=1) - Y|do(on sale=0) 와 같이 ITE를 구할 수 있는 것.
- 다만, 인과추론의 근본적인 문제(두 집단에 처치를 동시에 적용할 수 없다) 때문에 이론적으로 해당 식을 표현할 수 있다고 해도 데이터에서 반드시 이를 구해낼 수 있다는 뜻은 아니다.
잠재적 결과 potential outcome
- 처치가 t인 상태일 때, 실험 대상 i의 결과는 Y가 될 것이다.
- 사실적 결과: 관측할 수 있는 잠재적 결과 <> 반사실적 결과: 관측할 수 없는 잠재적 결과


- 가정 1: 잠재적 결과는 처치와 일치성이 있어야 한다.
- T로 지정된 처치 외에 숨겨진 여러 가지 형태의 처치는 존재하지 않는다.
- ex 1) 할인 쿠폰이 매출에 미치는 영향에 관심이 있을 때, 처치는 고객이 쿠폰을 받았다/안 받았다로 나뉜다. 하지만 실제로는 여러 번의 할인을 시도했다면, 일치성 가정을 위배한다.
- ex 2) 재무 설계사의 도움이 개인 자산에 미치는 영향에 관심이 있을 때, '도움'이라는 처치가 명확히 정의되지 않았다. 일회성 상담인지, 정기적인 조언과 목표 추적인지, 그 외인지, 모든 것인지,.. 모든 종류의 재무 조언을 하나의 범주로 묶을 시에 일치성 가정에 위배한다.
- 가정 2: 하나의 실험 대상에 대한 효과는 다른 실험 대상에 영향을 받지 않는다. (stable unit of treatment value assumption, SUTVA)
- 파급 효과 또는 네트워크 효과가 있는 경우, 이러한 가정은 위배된다.
- ex) 백신이 전염성 질환 예방에 미치는 영향을 알고 싶을 때, 한 사람에게 백신을 접종하면 그 사람과 가까운 사람들도 처치 받지 않았더라도 해당 질병에 걸릴 확률이 낮아질 수 있다. 이럴 경우 처치 효과가 실제보다 작다고 생각하게 된다.
독립성 가정(교환 가능성)은 인과추론의 핵심 가정이다. ← 잠재적 결과 Y가 처치 T와 독립적이라고 가정하는 것.
인과추론 문제는 보통 다음과 같이 두 단계로 나뉜다.
- 식별(identification): 관측 가능한 데이터로 인과 추정량을 표현하는 방법을 알아내는 단계
- 추정(estimation): 실제로 데이터를 사용하여 앞서 식별한 인과 추정량을 추정하는 단계
식별 과정
- 잠재적 결과 중 하나만 관측할 수 있으므로 개별 처치효과(ITE)와 같은 인과 추정량을 알 수 없다. → but, 관측 가능한 다른 수치를 찾아서 이를 관심 있는 인과 추정량을 찾는데 활용할 수 있다.
- 즉, 관측된 값인 실험군과 대조군의 평균 결과를 추정하여 관심 있는 인과 추정량을 구할 수 있다.
- 인과적 식별 = 편향을 없애는 과정
- 일반적으로 처치가 어떻게 배정되었는지를 알 수 있을 때 식별이 가능하다.
2장 무작위 실험 및 기초 통계 리뷰

잠재적 결과가 처치와 독립인 경우에 연관관계가 인과관계와 동일해진다.
- 처치와 결과가 독립적이다. (X) ← 처치와 결과가 독립적이라면 처치는 결과에 아무런 영향을 미치지 않는다는 뜻
- 처치와 잠재적 결과가 독립적이다. (O)
- 잠재적 결과와 처치가 독립성 가정을 만족하면, 실험군과 대조군의 평균을 비교하여 간단히 ATE를 구할 수 있다.
무작위 통제 실험(randomized control trial, RCT)이 인과추론의 가장 중요한 표준인 이유
- 무작위로 처치를 배정하면
- → 실험군과 대조군 간의 유일한 차이는 처치밖에 없어지고
- → 두 그룹의 결과 차이는 해당 처치에 따른 것으로 볼 수 있게 된다.
- → 즉, 처치와 잠재적 결과를 독립적으로 만든다.
하지만, 무작위 실험은 표본 크기가 작으면 '인과관계 식별'은 할 수 있어도 '인과관계 추론'은 어려울 수 있다.
- 표본 크기가 작으면 단순히 우연 때문에 지표가 매우 높거나 낮을 수 있기 때문 → 표본 규모가 클수록 우연이 작용할 가능성이 적다.
- 이러한 부정확성(불확실성)을 고려하는 방법: 추정값의 분산 계산, 신뢰구간 계산, 가설검정, etc.
- ex) 분산을 계산하면, 관측값이 기댓값(중심값)에서 얼마나 벗어났는지 알 수 있고, 이를 통해 불확실성을 정량화할 수 있다.
통계학은 무작위 오차에서 오는 불확실성을 다루는 과학이다. 우리는 통계를 사용해 불확실성을 보완할 수 있다.
3장 그래프 인과모델
인과관계를 그래프 구조로 시각화하여 표현할 수 있다. DAG(directed acydic graph, 방향성 있는 비순환 그래프)이라고도 부른다.

- 관측 불가능한 요소는 U로, 관측 가능한 요소는 X로 표현한다.
- 그래프의 각 노드는 확률변수이다.
- 화살표나 엣지를 사용하여 한 변수가 다른 변수의 원인이 되는지를 표현한다.
- 인과관계는 화살표 방향으로만 흐르지만, 연관관계는 양방향으로 흐른다.
교란요인(confounder): 처치와 결과 사이에 존재하는 공통 원인
조건부 독립성 가정(CIA, conditional independence assumption): 공변량 X 수준이 동일한 대상을 비교하면 잠재적 결과는 평균적으로 같다. = 무시가능성, 외생성, 교환 가능성
- 보정 공식(adjustment formula)
- 처치가 X 그룹 내에서 무작위로 배정된 것처럼 보인다면, X로 정의된 각 그룹 내에서 실험군과 대조군을 비교하고 각 그룹의 크기를 가중치로 사용해서 해당 결과의 평균을 구하는 방법. = 조건부 원칙
- 뒷문 보정: 교란 요인을 보정하여 뒷문 경로를 차단하는 과정
- 양수성 가정: X의 모든 그룹에 실험군과 대조군의 실험 대상이 반드시 존재해야 한다.
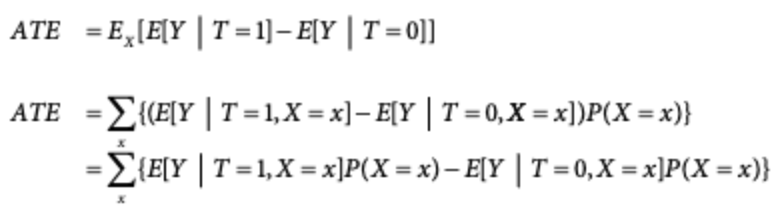
(스터디) 실무로 통하는 인과추론 with 파이썬 - PART 2에서 이어집니다.